Beberapa bulan ini saya sedang belajar ketrampilan menggunakan Python untuk Data Science. Salah satu ketrampilan yang diperlukan oleh seorang Data Scientist adalah mengumpulkan data (data extraction). Salah satu sumber data adalah: internet (tentu saja!). Salah satu teknik mengumpulkan data dari internet adalah dengan melakukan web scraping. Kita melakukan scaping untuk mengumpulkan data yang kita perlukan daris sebuah halaman web.
Kepustakaan yang saya pilih untuk melakukan scraping adalah Scrapy. Tulisan ini merupakan dokumentasi usaha pertama saya melakukan scaping. Tujuan saya melakukan scraping adalah mengumpulkan foto produk dari sebuah website. Disclaimer: saya dalah distributor dari brand tersebut dan saya memerlukan foto produk untuk ditampilkan di media sosial yang saya gunakan untuk memasarkan produk tersebut.
Cek Struktur atau Elemen dari Halaman Web
Sebelum melakukan scraping adalah perlu kita cek dulu struktur atau elemen-elemen yang ada dalam halaman web. Caranya dengan menggunakan tool yang sudah disediakan mayoritas web browser modern: "View Source" atau "Inspect". Jika menggunakan Google Chrome seperti saya, arahkan cursor ke arah bagian yang akan di "scrap" kemudian gunakan klik-kanan mouse dan pilih Inspect.
Maka browser akan menampilkan side bar yang menampikan elemen-elemen serta kode HTML dari halamn web tersebut. Untuk halaman web ini, foto produk berada dalam tag
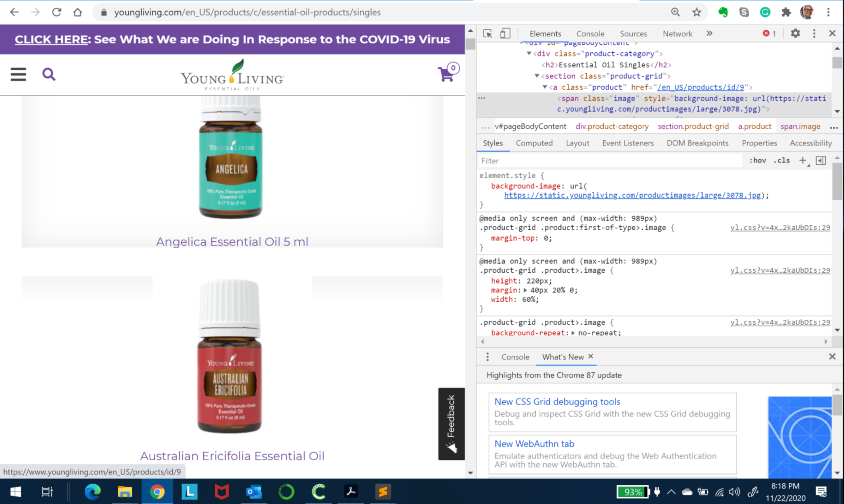
Membuat Script
Pertama, kita perlu import modul-modul yang diperlukan:
from scrapy import Selector
import requests
import re
Selanjutnya kita muat halaman web yang akan di-scrap dan buat instan Selector
page = requests.get("https://www.youngliving.com/en_US/products/c/essential-oil-products/blends").content
sel = Selector(text=page)
Setelah itu, ekstrak bagian dari halaman yang memuat alamat dari foto yang akan di download menggunakan xpath yang sesuai dengan inspeksi kita di atas:
x_path = '//a[@class="product"]/span[@class="image"]'
images_list = sel.xpath(x_path).extract()
Akan tetapi sayangnya, hasil esktrak masih "mentah"
<span class="image" style="background-image: url(https://static.youngliving.com/productimages/large/3080.jpg)">
</span>
Untuk mendapatkan alamat/url dari foto, saya menggunakan regex untuk "membersihkan" alamat yang saya perlukan
images = list()
for line in images_list:
x = re.search("https.*.jpg", line)
images.append(x.group())
Alamat/url foto-foto saya masukkan ke dalam list
Terakhir, menggunakan alamat yang sudah dibersihkan, saya menggunakan requests untuk mendownload foto ke dalam hard disk saya:
## Importing Necessary Modules
import shutil # to save it locally
## Set up the image URL and filename
for image_url in images:
filename = image_url.split("/")[-1]
# Open the url image, set stream to True, this will return the stream content.
r = requests.get(image_url, stream = True)
# Check if the image was retrieved successfully
if r.status_code == 200:
# Set decode_content value to True, otherwise the downloaded image file's size will be zero.
r.raw.decode_content = True
# Open a local file with wb ( write binary ) permission.
with open(filename,'wb') as f:
shutil.copyfileobj(r.raw, f)
print('Image sucessfully Downloaded: ',filename)
else:
print('Image Couldn\'t be retreived')
Selesai. Happy scraping